
파이썬 라이브러리 중 가장 흔하게 쓰이는 세 가지를 꼽으라면
pandas, numpy, matplotlib일 것이다.
간단한 개념을 정리하며 예제 실습을 해본다.
1. pandas(판다스)
판다스는 데이터 프레임 자료구조를 사용한다.
즉, 엑셀의 스프레드시트와 유사해 데이터 처리가 쉽다.
#실습
데이터 프레임에 들어갈 열 데이터 생성->list,zip으로 데이터셋 생성->데이터프레임 객체 생성->head로 확인
import pandas as pd
names = ['Bob','Jessica','Mary','John','Mel']
births = [968, 155, 77, 578, 973]
custom = [1, 5, 25, 13, 23232]
Baby=list(zip(names,births))
df=pd.DataFrame(data=Baby,columns=['names','births'])
df.head()#df.dtypes=열의 타입 정보
#index=행의 형태 정보
#columns=데이터프레임의 열 정보 요약
df.dtypesdf.indexdf.columns#특정 열만 출력하기
df['names']
#특정 인덱스만 출력(행)
df[0:3]
#필터링
특정 조건 : birth 열이 100보다 큰 데이터만
df[df['births']>100]
#평균값 계산
df.mean()
2. Numpy(넘파이)
Numerical python의 줄임말, 수치 계산을 위한 파이썬 라이브러리.
pandas/matplotlib 라이브러리의 기본 데이터 타입으로 사용되기도 함.
배열(array) 개념으로 변수 사용. 벡터, 행렬 연산 ok.
파이썬이 기본 자료구조로 리스트, 딕셔너리 등을 가지고 있듯
데이터 분석은 기본 자료구조로 넘파이 배열을 가짐.
넘파이 약어는 np.
import numpy as np#넘파이 배열 선언 : 1차원배열 3개, 2차원 배열 5개, 15개의 숫자 생성 : 0부터 14까지 15개의 숫자를 3,5차원으로 생성
arr1=np.arange(15).reshape(3,5)
arr1
#shape 호출해서 넘파이 배열 데이터 차원 확인 가능.
arr1.shape
#dtype으로 데이터 타입 확인 가능
arr1.dtype
#zeros() 함수로 데이터 생성 가능 : 0으로 채워진 넘파이 배열. 1은 ones()
arr00=np.zeros((3,4))
arr00
arr11=np.ones((3,4))
arr11
#twos도 될까? =>안됨
arr22=np.twos((3,4))
arr22#numpy 데이터 연산 + - * / 사칙연산
arr4 = np.array([
[1,2,3],
[4,5,6]
], dtype = np.float64)
arr5 = np.array([
[7,8,9],
[10,11,12]
], dtype = np.float64)
# 사칙연산을 출력합니다.
print("arr4 + arr5 = ")
print(arr4 + arr5,"\n")
print("arr4 - arr5 = ")
print(arr4 - arr5,"\n")
print("arr4 * arr5 = ")
print(arr4 * arr5,"\n")
print("arr4 / arr5 = ")
print(arr4 / arr5,"\n")
#이외에도 dot() 행렬 연산 등 많은 기능이 있음.
3. Matplotlib
데이터 시각화 라이브러리.
%matplotlib inline : 현재 실행중인 주피터 노트북에서 그래프 출력하도록 선언
%matplotlib inline
import matplotlib as plt
#plt.bar(x,y)로 그래프 객체를 먼저 생성해주어야 하고, 이 다음에 객체에 다른 요소 추가 가능.
#plt.show()로 그래프 출력.
names = ['Bob','Jessica','Mary','John','Mel']
births = [968, 155, 77, 578, 973]
custom = [1, 5, 25, 13, 23232]
y = df['births']
x = df['names']
# bar plot을 출력합니다.
plt.bar(x, y) # --> 막대그래프 객체 생성
plt.xlabel('names') # --> x축 제목
plt.ylabel('births') # --> y축 제목
plt.title('Bar plot') # --> 그래프 제목
plt.show() # --> 그래프 출력그런데 아래와 같은 에러가 발생했다.
AttributeError: module 'matplotlib' has no attribute 'bar'찾아보니 matplotlib.pyplot 으로 plt를 선언해주어야 하는데 빠뜨려서 다시 설치해주었다.
import matplotlib.pyplot as plt
하지만 나처럼 다크테마라면 예쁘게 보이지 않는다.
그래서 inline 말고, qt로 새 창을 띄워서 확인해본다.
(%matplotlib inline 앞에 #을 붙여 주석처리해준 후,
%matplotlib qt 라고 붙여준다)
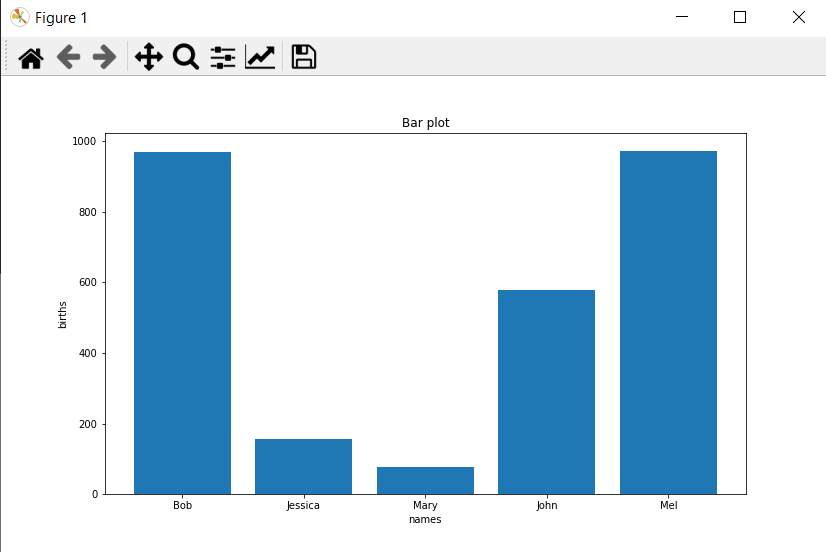
Good! 예쁘다. 나중에 글꼴 등을 설정하면 더 이쁘게 나오겠다.
다음으로는 산점도 그래프를 출력해보자.
#랜덤추출시드 고정->random.rand()함수가 넘파이 배열 타입의 난수 생성
#->arange() : 5 간격으로 0~100까지 숫자 생성->plt.scatter로 출력
np.random.seed(19920613)
#산점도 데이터 생성
x = np.arange(0.0,100.0,5.0)
y = (x*1.5) + np.random.rand(20) * 50
#산점도 데이터 출력
plt.scatter(x,y,c='b',alpha=0.5, label="scatter point")
plt.xlabel("X")
plt.ylabel("Y")
plt.legend(loc='upper left')
plt.title("scatter plot")
plt.show()
이전 글
2022.03.10 - [Data science] - 3초 안에 주피터노트북 다크 테마 설정(가상환경)
3초 안에 주피터노트북 다크 테마 설정(가상환경)
activate pybook(가상환경이름) 으로 가상환경을 실행해준 다음, jt -t 를 입력해서 테마 관련 설정을 확인한다. jt -t THEME을 누르면 테마 이름들을 확인할 수 있다. 다크 테마의 대표인 monokai로 설정해
limitt.tistory.com
2022.03.07 - [Data science] - [한 번에 해결] 주피터 노트북 & 아나콘다 설치하고, 기본 작업경로 설정 후 가상환경 만들기까지
[한 번에 해결] 주피터 노트북 & 아나콘다 설치하고, 기본 작업경로 설정 후 가상환경 만들기까지
파이썬을 이용한 데이터 분석에서, 셀 단위로 코드를 입력하고 바로바로 결과를 확인할 수 있는 아나콘다의 주피터 노트북은 굉장히 편리하다. 컴퓨터를 리셋하면서 주피터 노트북도 함께 없어
limitt.tistory.com
*본문 출처 : [이것이 데이터 분석이다 with 파이썬] 저자 윤기태, 한빛미디어
'Data science' 카테고리의 다른 글
| 트위터 twitter API 개발자 계정 신청 및 apps 등록 후기 : 바로 승인 성공 (0) | 2022.04.13 |
|---|---|
| 파이썬 file_path 사용하기 : FileNotFoundError (0) | 2022.03.11 |
| 3초 안에 주피터노트북 다크 테마 설정(가상환경) (0) | 2022.03.10 |
| [한 번에 해결] 주피터 노트북 & 아나콘다 설치하고, 기본 작업경로 설정 후 가상환경 만들기까지 (0) | 2022.03.07 |
| [독후감] 빅데이터 기초 & 인공지능 시대의 비즈니스 전략 (0) | 2022.03.06 |




댓글